I am one of those people who find a lot of satisfaction in learning new things. I have a curious mind interested in many subjects, especially in the technological field. Since I was a child, I was captivated by those black boxes called computers. Luckily I always had one at home, from the XT-8086 to the Pentium and the newer models. It was natural for me to study Computer Sciences, which led me to explore this endless world.
Things were simpler when I was a teenager. The internet was emerging, and I kept myself informed by reading magazines like Computer World or PC Magazine. Everything was very digestible. Things have become more complicated in recent years. Since the advent and popularization of subscription-based content services (RSS, Audible, Netflix, Tidal, etc.) I have been overwhelmed by an avalanche of information that is increasingly difficult to process due to lack of time.
This situation is probably one of the reasons why I am so interested in AI and cognitive sciences. At some point, we should (voluntarily and with total control) be able to sit in a chair and plug our brains into an open-source interface to learn things in moments. If you who are reading me are working on something like this, contact me :)
But until this disruptive technology comes, and we are ready for it, the alternatives orbit on improving the selection of the content to consume, and for that, Machine Learning seems to be the right tool.
This article focuses on what I consider a fascinating application of NLP: Summarization.
Let's get started!
Table of Contents
Summarization is not an easy and generalistic task
I consider that a personal touch is required to create an optimal summary. I mean, the text you make will probably be different from the one I make (I'm talking about nuances beyond capturing the underlying topic). In other words, as we are interested in different things, what we'll highlight as important will be what resonates most with us.
I believe that a summarization model is only the gateway. The underlying complexity is to fine-tune the model to your needs. And therein lies the dilemma. Where do you get at least a thousand summaries that reflect your needs and desires? What if your interests span different contexts? Would you need at least a thousand summaries for each of them? Would you have to fine-tune the same model with each context? Will it be better to have a separate model for each different context?
Obtaining acceptable results seems complex. For example, if you do one summary a day, you will need at least three years to get a training dataset of a thousand samples, and I don't know if it is enough to fine-tune the model you have chosen.
For the moment, I consider that due to the above limitations, current summarization techniques are helpful if taken as a reference only. But this can quickly flip. At the current speed of changes, we might have the next Transformer just around the corner.
Despite this, I still find it interesting to learn about neural summarization techniques. So, let's continue.
Approaches to text summarization using Machine Learning
We can summarize a document using statistical or neural models. Extractive summarization uses unsupervised techniques, such as LDA. These methods extract the most significant sentences and concatenate them in order of importance. Unfortunately, it does not work as well as neural models. Let's look at each approach in more detail.
As I mentioned in the previous paragraph, this technique concatenates the most important sentences from the original text. This type of summarizer performs three tasks:
- Create an intermediate representation of the original text. The idea is that this representation contains the most prominent aspects of the input text.
- Score the sentences using the previous representation.
- Construct a summary by selecting the sentences with the highest scores.
To create the intermediate representation of the input text, we can use a couple of approaches:
Topic representation
In general, this approach tries to find the most salient topics of a document. There are several techniques to achieve this. The most outstanding ones are Latent Semantic Analysis (LSA) and Bayesian Topic Models.
LSA is an unsupervised method for extracting a representation of text semantics based on observed words.
Allahyari et al., 2017
LSA determines which sentences are more important by counting the frequency of the words using TFIDF and then using dimensionality reduction techniques like Singular Value Decomposition (SVD) to determine the topics, their weights, and how much a sentence represent a topic.
Bayesian topic models are probabilistic models that uncover and represent the topics of documents.
Allahyari et al., 2017
This kind of model often uses the Kullback-Liebler (KL) Divergence to score the sentences by finding the difference of their underlying probability distributions. As a good summary should be similar to the input text, their KL divergence will be minimal.
The Latent Dirichlet Allocation (LDA) is a SOTA generative probabilistic model. This model extracts topics from a collection of documents. LDA is composed of two Dirichlet distributions used as input for two multinomial distributions.
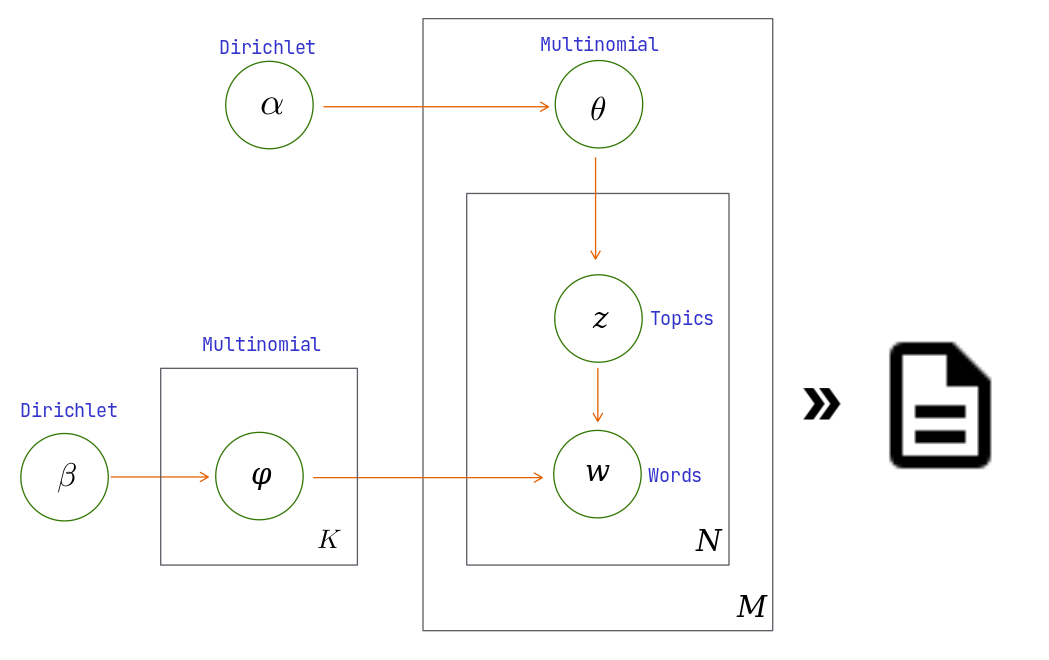
Source: Own
Where the α Dirichlet distribution describes the documents/topics distribution, and the β Dirichlet distribution represents the topics/words distribution. The collection of all αk and βw values are used by the multinomial distributions in the generative phase of LDA. The length of the generated documents is given by a Poisson distribution.
As it is expensive to compute the total probability of LDA, we can use alternative approximation methods like Gibbs Sampling at inference time.
This type of approach is not easy to understand and requires deepening in advanced statistical concepts. I could dedicate time and effort to these techniques and work on my implementation, but the preliminary tests I did have not given me satisfactory results. For this reason, and in my opinion, the effort vs. "model's performance" tradeoff is imbalanced, and I prefer to focus my energy on neural summarization.
Indicator representation
At this point, I do not want to dwell too much on statistical methods since, for the moment, I don't think I will apply them in my exploration of NLP. However, I do want to comment briefly on this approach.
In short, these methods use indicators/features like sentence length, the position of the sentence in the document, usage of certain phrases, etc., to determine the importance of each sentence. With this information, we rank the sentences instead of using the main topics as measures of prominence.
Graph, similarity methods, and counting methods like TFIDF are used to represent a document as a connected graph where vertices represent sentences and edges indicate how similar a couple of sentences are.
Abstractive methods
These complex and expensive techniques use DL models that shorten and paraphrase the input text. As these are generative methods, the output summary might contain words not present in the input. A benefit of these methods is that they produce grammarly correct text. Something that might not be true with the extractive approaches.
As we'll see below, these methods produce SOTA results, so their complexity and computational cost become less important.
SOTA models for summarization
PEGASUS
PEGASUS is a transformer-based encoder-decoder model created by Google in 2020 (Zhang et al.). The Google team explored "pre-training objectives tailored for abstractive text summarization". They also "evaluate[d] on 12 downstream datasets spanning news, science, short stories, instructions, emails, patents, and legislative bills".
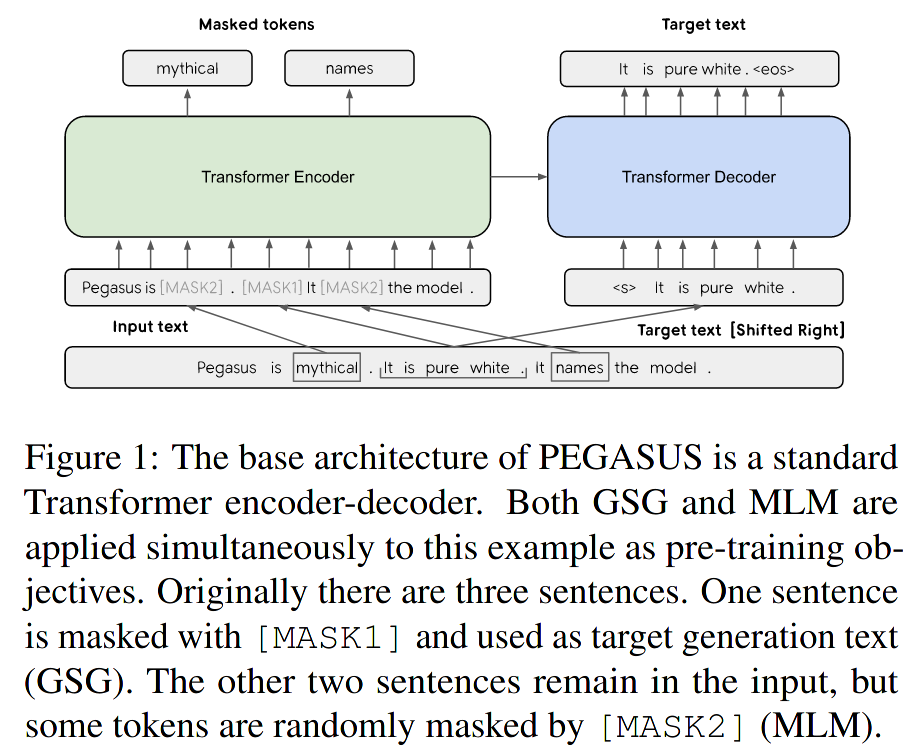
Source: Zhang et al., 2020. The Masked Language Model was not included in PEGASUS Large since it didn't help to increase performance when fine tuning with larger pre-training steps (500k).
Zhang et al. discovered that masking entire sentences and reconstructing them worked well as a summarization pre-training objective, especially if the masked sentence is relevant in the context of the document. In Zhang et al. words:
[...] this objective is suitable for abstractive summarization as it closely resembles the downstream task, encouraging whole-document understanding and summary-like generation.
As a measurement of importance to select the top m sentences, Zhang et al. used the ROUGE1-F1 between the masked sentence and the rest of the document. PEGASUS obtained fantastic results with Google's (closed source?) HugeNews dataset, "a dataset of 1.5B articles (3.8TB) collected from news and news-like websites from 2013-2019."
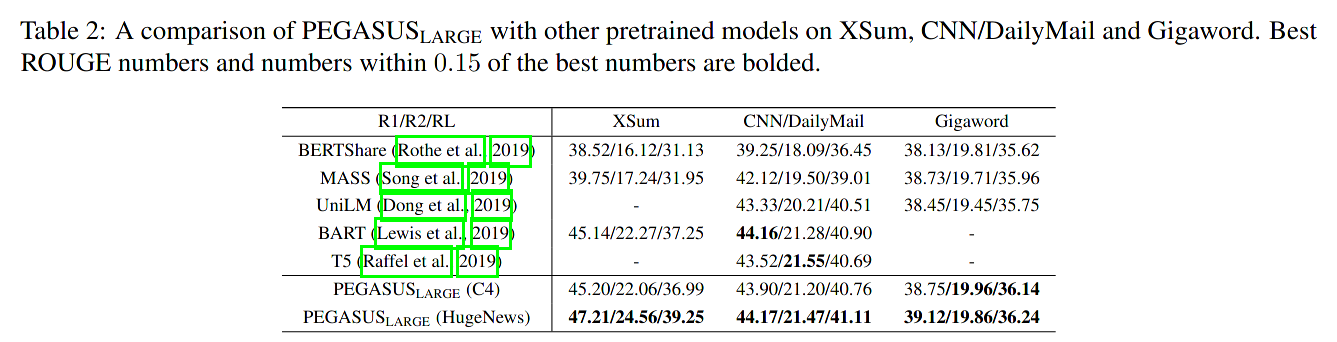
Source: Zhang et al., 2020.
BART
It is a denoising autoencoder that maps a corrupted document to the original document it was derived from.
Lewis et al., 2019
This model by Facebook uses the Transformer architecture for language generation. It is trained by corrupting text with an arbitrary noising function (e.g., token masking, sentence permutation, text infilling, etc.) and learning a model to reconstruct the original text.
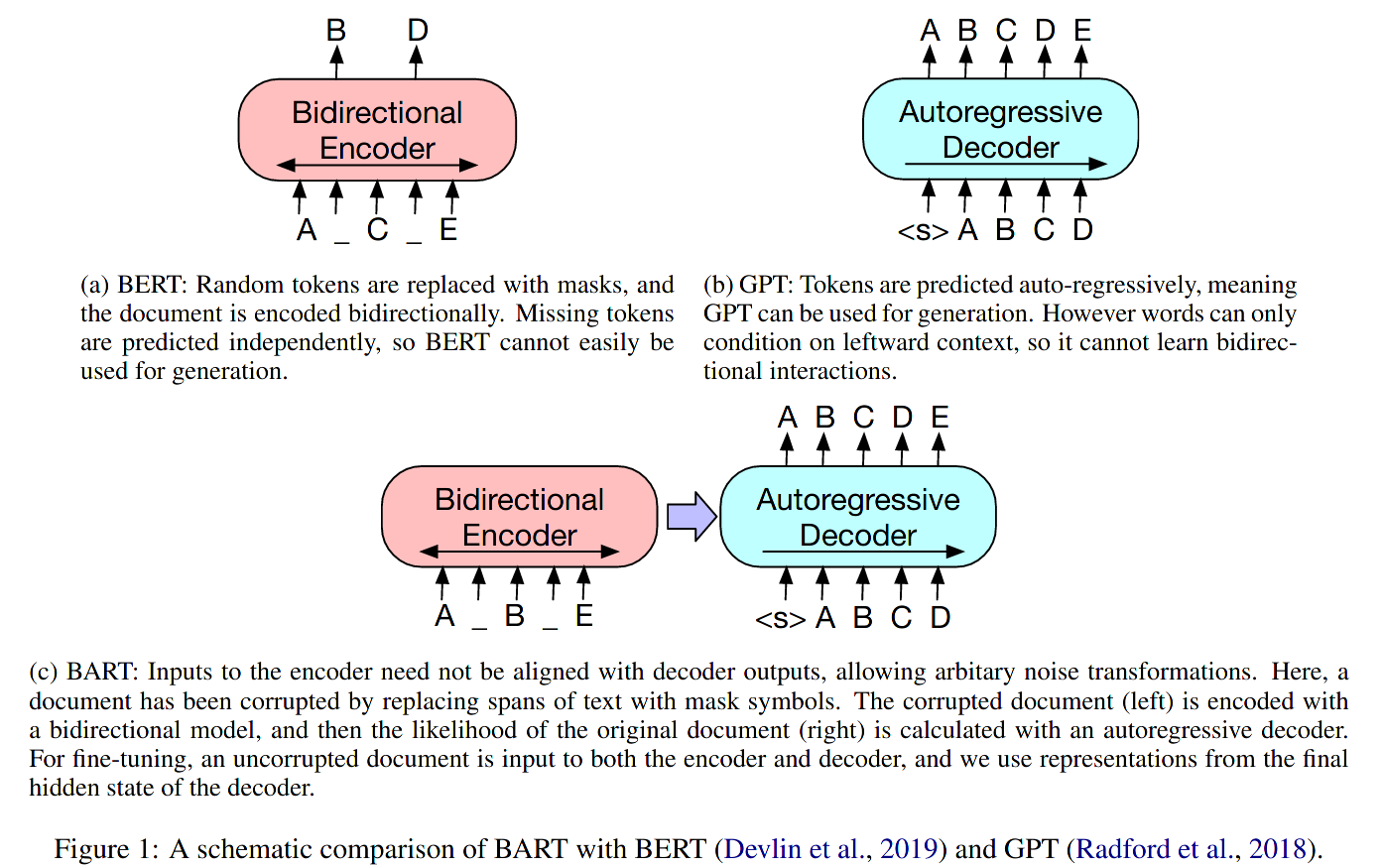
Source: Lewis et al., 2019
Architecture-wise, BART uses GeLU instead of ReLU and initialize parameters from N(0,0.02). Also, it doesn't use an additional FFN before word prediction as in BERT.
Among all the noising techniques tried, two produced better results:
- Random shuffling of the order of the original sentences.
- Using an in-filling scheme, where arbitrary length spans of text (including zero-length) are replaced with a single mask token.
According to Lewis et al., BART is particularly effective when fine-tuned for text generation. In other words, as BART has an autoregressive decoder, it is effective in abstractive question answering and summarization.
In both of these tasks, information is copied from the input but manipulated, which is closely related to the denoising pretraining objective. Here, the encoder input is the input sequence, and the decoder generates outputs autoregressively.
Lewis et al., 2019
The model was pre-trained in two sizes:
- Base: 6 layers.
- Large: 12 layers, hidden size of 1024, batch size of 8000, 500K training steps, GPT-2 byte-pair tokenization, noising functions were text infilling and sentence permutation (30% of tokens were masked in each document, permutation was applied to all sentences).
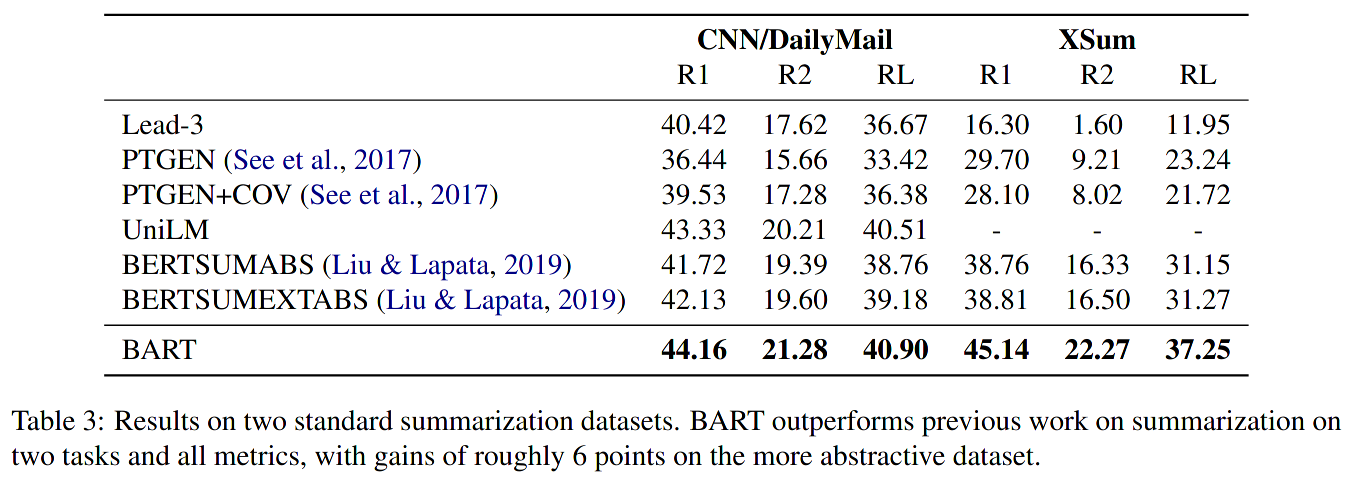
Large model results. Source: Lewis et al., 2019
OK, both models sound great, but which one to choose? It would be necessary to implement them, pre-train them, optionally fine-tune them and make some inferences to determine which one best fits our needs.
The whole process will take a lot of time since we also need to consider the datasets to use. That will directly affect the output of the model.
However, thanks to the community, it is now possible to use pre-trained models with ease and speed. With TensorFlow Hub, PyTorch Hub, or HuggingFace, you can enable and accelerate experimentation and selection of architectures and models for almost any NLP task.
PEGASUS is not available in PyTorch Hub or TensorFlow Hub, but it is available in HuggingFace.
I admire HuggingFace and its mixed business model. For one thing, their codebase is open source, but they have a paid tier where they host pre-trained models for inference where each API call is charged. It is also possible to fine-tune the pre-trained models on the cloud managed by them. They also provide professional services, on-premise low latency solutions for inference, and optimization toolkits to speed up production performance. Yeah! knowledge/experience is power.
Going back to my experiments, what I did was to determine which datasets to use. Then, I decided on some rules for experimentation, created a script to try the models with the Transformers library, analyzed the outcomes, and selected a model. Let's see the details in the following sections.
Dataset selection
I think this is the first relevant element to consider when selecting a model for summarization. I have explored three summarization datasets with different characteristics.
XSum
The "Extreme Summarization" (XSum) Dataset was created by The Natural Language Processing Group at the University of Edinburgh as described in the paper "Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization" by Narayan et al., 2018. It contains "226,711 Wayback archived BBC [single-documents]" with accompanying single sentence summaries from 2010 to 2017, "covering a wide variety of domains (e.g., News, Politics, Sports, Weather, Business, Technology, Science, Health, Family, Education, Entertainment and Arts)." The summaries were professionally written by the authors of the articles as part of their metadata.
Let's take a look at one sample:

Source: HuggingFace
CNN / Daily Mail
This dataset is a multi-sentence summaries corpus based on Hermann et al.'s "Teaching Machines to Read and Comprehend" paper of 2015. The articles come from CNN and Daily Mail websites from 2007 to 2015.
The original corpus, created for machine-reading comprehension (Hermann et al., 2015), was later modified for summarization by Nallapati et al., 2017.
In all, this corpus has 286,817 training pairs, 13,368 validation pairs, and 11,487 test pairs, as defined by their (Hermann et al.) scripts. The source documents in the training set have 766 words spanning 29.74 sentences on average, while the summaries consist of 53 words and 3.72 sentences. The unique characteristics of this dataset such as long documents, and ordered multi-sentence summaries present interesting challenges, and we hope will attract future researchers to build and test novel models on it.
Nallapati et al., 2017
Each article from the corpus contains a set of bullet points that summarize some aspect of the article, for example:

Source: DailyMail
Hermann et al. used these bullets points to create their document/query/answer triplets. Later, Nallpati et al. concatenated the bullet points to construct anonymized multi-sentence summaries.
Finally, See et al., 2017 (my teacher Abi! :) released a script to produce the non-anonymized version of the CNN / Daily Mail summarization dataset. This script corresponds to the ACL 2017 paper "Get To The Point: Summarization with Pointer-Generator Networks." HuggingFace is currently offering this version of the dataset.
This is how one example looks like:
Summary: Thousands of girls are adopted out of China each year, ending up in homes around the world . Many of them find identity and purpose in returning to China to visit their roots . Adoptive parents often choose to travel back to China frequently with their adopted children . Many adoptive parents feel it a duty to teach their children about where they came from.
☙
Hong Kong (CNN) -- When Maia Stack returned to the pagoda, or tower, where she had been abandoned as a baby she was overwhelmed by what had happened there 11 years earlier. "I remember thinking, 'Wow, I wonder if my birth family hid behind those bushes or something'" said Stack, now 18 years old, on returning to Hangzhou, China. "I felt very disengaged throughout the entire process. I kind of removed myself from the situation because it was too emotionally challenging." Stack is one of tens of thousands of children -- 95% percent of whom are girls -- who have been adopted from China since its government ratified international adoption in 1992. In 1979, Chinese officials introduced the one-child policy requiring that couples have only one child to slow the country's massive population growth. Could China's one-child policy change? With only one chance to pass on the family name, many Chinese couples are unhappy having a girl and either abort the pregnancy or abandon the baby. Because of this, China is one of the easiest countries from which to do an international adoption, according to ACC, a U.S.-based adoption agency that specializes in China. The process takes around two years and costs between US$19,000 and $23,000. Many of those adoptees eventually visit China to experience their heritage first-hand. Being Chinese helped to define Stack's childhood growing up in Milwaukee, Wisconsin. She and her sister, who is also adopted from China, attended a Saturday school to learn Chinese language and culture while other children were playing soccer or baseball. Stack was home schooled until partway through high school and attended a group of students that never treated her differently. However, when she started attending a charter school where she was the only Asian in a group of 40 students things changed. "I did feel much like an outsider. I had the darkest skin, the only head of black hair in a sea of blond and brown," she said. "As the 'representative Asian,' the kids fed back to me the typical stereotypes about Asians -- super smart, good in math, short ... While they didn't mean harm, it did hurt." Spending four-and-a-half months in Beijing in 2011 studying Mandarin changed her outlook. "I feel very proud to be both Chinese and American," she said. "I know that those things will always be a part of me whether I live in China or in America." Today, Stack is a board member of China's Children International -- an organization founded by high school girls to bring together Chinese adoptees around the world. Amy Cubbage and her husband, Graham Troop, adopted their daughter June from China when she was two years old. After deciding they wanted children, the couple chose to adopt internationally because of the positive experience Cubbage's sister had adopting children from Russia. They applied for a non-special needs adoption in 2006, Cubbage said. But after nearly two years and no match, they put their names on the list for special needs children -- meaning the child requires some form of medical treatment. Finally in the fall of 2008, the couple was connected with June, who had been born with a cleft lip that has been repaired. As she grew older, June enjoyed attending Chinese cultural events so much that, at the age of five, she asked her parents if she could visit China. "We were going to take her back eventually," said Troop, a librarian in Louisville, Kentucky. "I was a little surprised because it was a little early, but we felt that if she was asking to go she must have a need to go." The family made the trek to China last month visiting the Great Wall, Beijing's Tiananmen Square and June's orphanage in Guangxi province, among other sites. "She was joyful the whole time," Cubbage, a lawyer, said of her daughter. "It was clear that she had a large connection to the place." Upon visiting with the foster family that tended to their daughter June's parents were overcome with emotion. "We could see the love that they had on their faces for her and the sadness that they didn't have her anymore," Cubbage said. "I know they are happy that she was adopted but it was easy to see that they were sad too." Six-year-old June already shows a great deal of interest in her Chinese heritage, but it's not always easy to explain. "She asks why her parents couldn't take care of her and we try and answer that as best as we can. It's hard," her father said. "(Hearing about her adoption) is sort of a comfort to her. She likes to hear her story told." The family plans to return to China regularly. "The bottom line for us is that we chose to do an international adoption. She didn't. She didn't have any other choice," Cubbage said. "So I feel as a mom it is my responsibility to teach her." Jenna Murphy* and her husband are taking their five-year-old daughter to China in September -- something they decided before they even brought her home. "We're doing it in stages. She won't go back to the province where she was born this time," Murphy said. "We will just go to the major cities and the touristy, lovely places." When they picked their daughter up from the orphanage, she was 10 months old and could barely sit up, but after bringing her home to Australia her development quickly improved. Murphy said she wants her daughter to have a positive opinion of her birth country despite the challenges she has already faced in life. "I don't want her to think 'they didn't want me'... or for it to be even in the realm of possibility," Murphy said. "I want her to see China as a good thing." As for Stack, the high school senior said she wants to take a year off before college to volunteer in a Chinese orphanage. "I'm so blessed to have been adopted," she said. "I feel compelled to go back to China and volunteer and give back to the kids that weren't adopted." *Name has been changed to protect her from South Australian law prohibiting adopted children from being identified in the media.
Multi-News
A dataset by Fabbri et al. for the ACL 2019 paper "Multi-News: a Large-Scale Multi-Document Summarization Dataset and Abstractive Hierarchical Model." Fabbri et al. used the summaries from the "newser" website and incorporated the original article from different sources.
Newser is a news curator with a kick. Our editors hand-pick the best stories from hundreds of US and international sources and summarize them into sharply written, easy-to-digest news briefs.
newser.com
Multi-News only considers those Newser documents that have between 2 and 10 links to the original articles. The dataset is relatively small compared to XSum and CNN / Daily Mail. It has 56,216 Newser documents in an 80% -10% -10% split.
It is relevant to observe that this is a dataset for multi-document summarization. Each training example will contain one or more documents used to produce a summary. As this is not my use case, I won't test any model with it.
The generation technique
We can tweak the generation process to obtain satisfactory results. In my case, I don't like one-sentence summaries. Also, we can choose to use a search or sampling approach when generating the output sequence.
HuggingFace has gently implemented several decoding algorithms like Beam Search, Top-k sampling, and Top-p sampling in their Transformers library. Testing and trying them is as easy as passing some extra parameters to the generate method.
Now, which approach works better for my use case? Should I take a search approach like Beam Search, or better the sampling one? I decided to try them both and compare the results.
To make the experimentation easier, I decided to stick to Beam Search and Top-k plus Top-p sampling.
Running experiments
These are the experimental parameters I followed:
- Try only large models.
- Try BART (with and without distillation) and PEGASUS only.
- Use XSum and CNN / Daily Mail datasets
- Use Beam search and Top-p/k sampling.
Regarding the input corpus, I started with a small test set composed of three articles with less than 1024 words since that is the model's maximum sequence length. I summarized the articles and used those summaries as a Gold Standard. You can check the articles' metadata here. For evaluation, I followed an intrinsic and extrinsic approach. Meaning, I used the ROUGE1 and ROUGEL metrics to have a numerical sense of which combination might provide better results. Also, I reviewed all the models' summaries to confirm what the metrics were saying. As a reference, these are the results of my intrinsic evaluation:
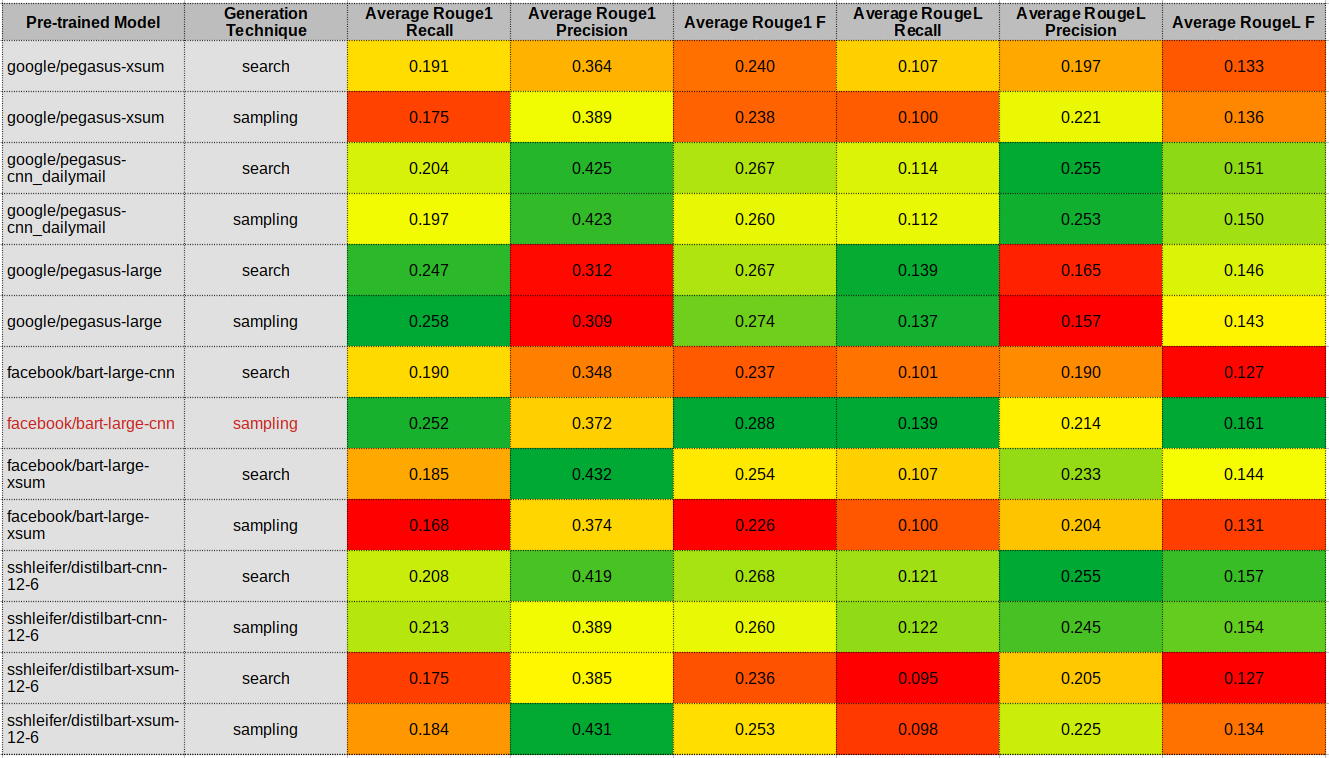
Source: Own
I made a bash script to run all possible combinations with a small Python script for inference. You can check the entire code here. The complete execution took about 40 minutes on my laptop.
My pick and impressions
At first, I was impressed by the google/pegasus-xsum model with a sampling approach, but the results were not consistent across the test set. Honestly, no model produced consistent results. Some summaries captured, more or less, the most salient ideas from the articles, but in general, none got close to my Gold Standards. Many summaries looked like extractive summaries. I saw a lot of sentence copying. Some summaries contain text from outside the input dataset (which is fine, but how can we be sure the generated text is correct without verifying ourselves?). Some others produced incoherent or contradictory text.
In a way, this outcome was predictable. I suppose the context of the pre-trained models might not correctly approach the underlying PDF describing the articles in my test set (or area of interest). I would have to finetune the pre-trained models with my gold standards to have better results.
Nevertheless, using these pre-trained models almost out of the box, as a reference, with this simplicity is just awesome. And hey, everything depends on how we use them. Showing one of the summaries as a reference and then, with that, deciding if it is worth dedicating our time to read it is a perfectly valid use case to me (if the title, subtitle, or TLDR sections were not enough).
Anyways, as indicated by the intrinsic evaluation results, confirmed by my extrinsic evaluation, and reconfirmed by HuggingFace's Hosted inference API, I selected the facebook/bart-large-cnn model with a sampling generation technique.
Next steps
OK, now what? Should I code myself the facebook/bart-large-cnn model and use another dataset like Multi-News, Reddit's TIFU, or NEWSROOM? Should I fine-tune it (well, start creating more summaries)? Should I deploy it to a production-like environment and see how to accelerate inference time to make it usable?
I guess I'm going to start by adding the selected model to a tool I'm building to help me digest better the overwhelming content I receive each week, and then, not sure. Perhaps I should look again at the extractive approaches to see if they help to complement an abstractive summary adding some missing main topics/ideas.
What is clear to me is that it is indispensable to be alert and up to date with the latest trends from the NLP community. Who knows, maybe the "next Transformer" is around the corner, and the whole panorama changes drastically.
I leave you with a reflection thanks to Jason Kottke. Thanks for reading. See you next time!
🤔
